
Rozo, L., Calinon, S. and Caldwell, D.G. (2014)
Learning Force and Position Constraints in Human-robot Cooperative Transportation
In Proc. of the IEEE Intl Symp. on Robot and Human Interactive Communication (Ro-Man), Edinburgh, Scotland, UK, pp. 619-624.
Abstract
Physical interaction between humans and robots arises a large set of challenging problems involving hardware, safety, control and cognitive aspects, among others. In this context, the cooperative (two or more people/robots) transportation of bulky loads in manufacturing plants is a practical example where these challenges are evident. In this paper, we address the problem of teaching a robot collaborative behaviors from human demonstrations. Specifically, we present an approach that combines: probabilistic learning and dynamical systems, to encode the robot's motion along the task. Our method allows us to learn not only a desired path to take the object through, but also, the force the robot needs to apply to the load during the interaction. Moreover, the robot is able to learn and reproduce the task with varying initial and final locations of the object. The proposed approach can be used in scenarios where not only the path to be followed by the transported object matters, but also the force applied to it. Tests were successfully carried out in a scenario where a 7 DOFs backdrivable manipulator learns to cooperate, with a human, to transport an object while satisfying the position and force constraints of the task.
Bibtex reference
@inproceedings{Rozo14ROMAN,
author="Rozo, L. and Calinon, S. and Caldwell, D. G.",
title="Learning Force and Position Constraints in Human-robot Cooperative Transportation",
booktitle = "Proc. {IEEE} Intl Symposium on Robot and Human Interactive Communication ({Ro-Man})",
year="2014",
address="Edinburgh, Scotland, UK",
pages="619--624"
}
Video
This video shows the experimental results of a learning approach in human-robot cooperative transportation task.
Demonstration phase- The robot is kinesthetically guided by a human teacher, who shows the robot its collaborative behavior while transporting an object with its human partner.
- Note that different starting and target locations of the object are set across demonstrations, which allows the robot to generalize to new positions during reproduction by exploiting a task-parametrized formulation of Gaussian mixture model.
- Notice that the teacher shows the robot not only the trajectory to follow (given the start and target positions), but also the force needed to be applied to the object.
- Once the robot has learned the task, it is able to carry out the collaborative skill with the user successfully. The robot is able to handle both position and force constraints of the task.
- Three different reproductions are shown. The first and second reproductions display two executions of the task with different start and target locations of the object. The third reproduction shows the robot's behavior when the human partner applies a different force to those sensed during the demonstration phase. Note that the robot adapts to these force perturbations while still following a similar path to the desired trajectory.
- All reproductions are followed by an animation showing the Gaussian components of the task-parametrized model, the trajectory followed by the robot and the attractor path. Also, we can observe three different projections of the resulting trajectories and the applied force during the reproduction.
Source codes
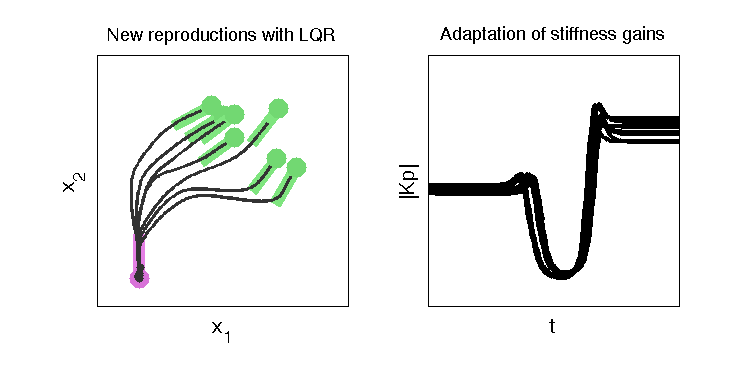
Demonstration a task-parameterized probabilistic model encoding movements in the form of virtual spring-damper systems acting in multiple frames of reference. Each candidate coordinate system observes a set of demonstrations from its own perspective, by extracting an attractor path whose variations depend on the relevance of the frame through the task. This information is exploited to generate a new attractor path corresponding to new situations (new positions and orientation of the frames), while the predicted covariances are exploited by a linear quadratic regulator (LQR) to estimate the stiffness and damping feedback terms of the spring-damper systems, resulting in a minimal intervention control strategy.
Download
 Download task-parameterized tensor GMM with LQR sourcecode
Download task-parameterized tensor GMM with LQR sourcecode
Usage
Unzip the file and run 'demo01' in Matlab. Several reproduction algorithms can be selected by commenting/uncommenting lines 89-91 and 110-112 in demo01.m (finite/infinite horizon LQR or dynamical system with constant gains). 'demo_testLQR01' and 'demo_testLQR02' can also be run as examples of LQR.
Reference
- Calinon, S., Bruno, D. and Caldwell, D.G. (2014) A task-parameterized probabilistic model with minimal intervention control. Proc. of the IEEE Intl Conf. on Robotics and Automation (ICRA).